Building a Regionally-Aware Model Router
March 10, 2026

March 10, 2026
During a recent technical evaluation, an NVIDIA infrastructure engineer asked us: "How do you failover once the request has been routed to the edge?" The question was probing for the classic mistake of putting a smart router in the hot path. We walked through the architecture: DNS-layer decision on first contact, edge metrics driving the selection, consecutive requests going direct to the node, SDK handling failover with a cached candidate list. The response was a nod.
Most inference platforms make the same architectural mistake. Every request transits a central load balancer or API gateway before reaching a GPU. The centralized gateway considers load, health, and geography. And it adds 50-200ms of dead time before inference even starts.
For batch workloads and chatbots, that's fine. For voice agents operating on human conversational timing, where the modal gap between turns is 200 to 300ms (Levinson & Torreira, 2015), a centralized routing hop can consume 30 to 60 percent of your entire latency budget before a single token is generated.
At PolarGrid, we started from a different design constraint: model routing at the edge means the routing decision happens once. After that, the client talks directly to the edge node. No round-trip to a central router on every request. No additional network hops between the user and the GPU running their inference.
This post walks through our inference request routing design: how we built that system, what we tried that didn’t work, and the hard problems we’re still solving.
Centralized DNS is the obvious solution. Configure Route53 with latency-based routing, point a single hostname at your edge fleet, and let DNS resolvers return the IP of the lowest-latency region. Clean, simple, and almost entirely server-side.
We started here.
The first problem is measurement accuracy. Route53 measures latency from the DNS resolver's location, not the client's location. When a user in downtown Toronto is routed through a corporate DNS server in Chicago, or when a mobile carrier's resolver sits in a data center three states away, the latency estimate is measuring the wrong network path. Any layer between the client and the resolver breaks the geographic assumption that DNS routing depends on.
The second problem is time. DNS resolution adds 10 to 50ms before the first packet flies. On a 300ms latency budget, that's significant. And TTL caching creates a staleness window. Even a 30-second TTL sounds responsive until a node goes unhealthy, and clients keep hitting it for another half-minute because their resolver cached the old answer. In voice, 30 seconds of stale routing is a dropped call.
The third problem is awareness. DNS knows geography, but not GPU queue depth, model availability, or per-node load. A node can be geographically closest to the client and also completely saturated, with 20 requests queued on its Triton server. DNS will keep sending traffic there.
DNS is a useful geographic filter and is the first step in inference routing. But region-aware serving demands more.
Our routing logic rests on a three-layer architecture for AI region-aware serving, where each layer operates at a different timescale and granularity.
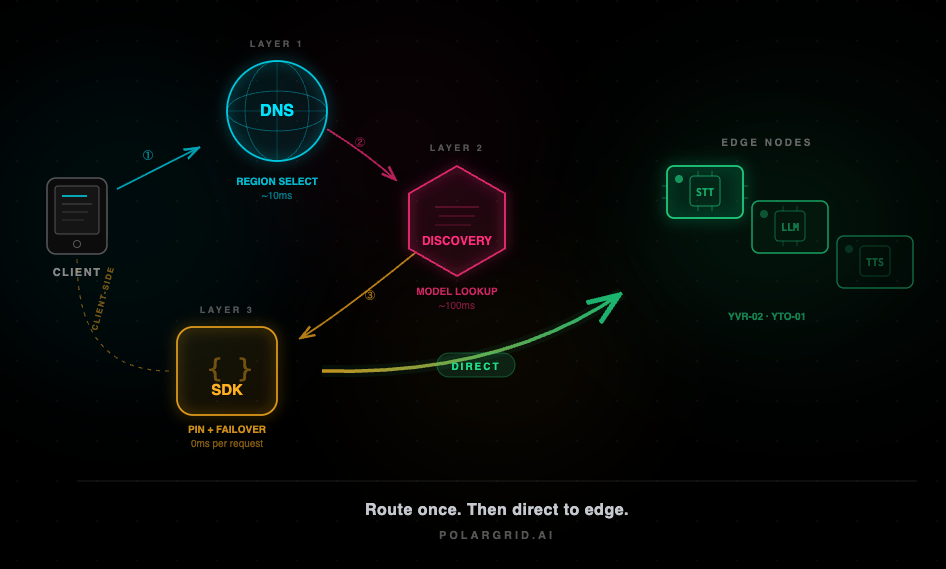
Anycast DNS gets the client to the right continent and region. This is the blunt instrument. It handles whether to send the request to Toronto or Vancouver. It does not handle which node within that area
Anycast DNS resolves in roughly 10ms globally. WebSocket support is native, which matters for voice streams. The key property here is that the DNS network is distributed enough that we're not adding a centralized hop. The client reaches a PoP near them, which connects to our nearest edge.
Once the client is in the correct region, it needs a low-latency model lookup to select the appropriate node. This is where the real routing intelligence lives.
On initialization, the SDK calls our discovery endpoint. It returns a ranked list of candidate edge nodes with the current metadata: region identifier, available models, health status, and aggregate load metrics. The SDK then pings each candidate in parallel, measuring actual round-trip time from the client's specific network position.
This takes roughly 100ms total. The result is a node ranking based on real measured latency from that specific client, not a heuristic based on geographic coordinates or resolver location. A user on a congested ISP in Toronto might find that a Montreal node is faster than the Toronto node, which is 20km away. DNS alone would never surface that.
The discovery API itself aggregates edge metrics by each node: current queue depth, active model list, inference latency percentiles, and health status. It pre-computes a weighted score for each node and returns the candidates in ranked order. The weights are tunable per deployment.
Once the SDK selects a node, it pins to that node for the duration of the session. There is no central hop, and the autorouter is not in the data path. Every subsequent request goes directly to the edge.
The SDK caches the candidate list and monitors latency in real time. If response times exceed a configurable threshold or a request fails outright, the SDK tries the next-best node from its cached list. If the list is stale (older than a configurable window), it re-probes. Edge nodes can also signal the SDK to migrate via response headers before a hard failure occurs, giving the client a chance to switch proactively rather than reactively.
Thus, consecutive requests never transit a central router. The routing decision gets made once, at session initialization. Everything after that is direct client-to-edge.
The edge components sit at *.edge.polargrid.ai inside the Secure Zone, a hardware-isolated Kata VM environment that separates the public gateway layer from the GPU performance zone. This isolation means that even if a public-facing API endpoint is compromised, the attacker cannot reach the Triton servers or unencrypted model weights in VRAM.
The edges contribute to the routing decision via four factors:
The total overhead of a routing decision is under 5ms. All scoring is pre-computed against cached metrics.
There is a core tension in intelligent inference request routing. The more factors you consider, the more computation the decision requires, and the more latency you add. A router that takes 50ms to choose the optimal node has defeated its own purpose.
We resolved this by separating the decision from the data path.
In a proxy-style architecture, the request flow is: client sends a request to the router, the router evaluates nodes, the router forwards the request to the selected edge, the edge processes and responds through the router. Every request pays the routing tax.
In our redirect-style architecture, the request flow on the first call is: the client asks the discovery API for candidates, probes candidates, and connects directly to the best node. Every subsequent request goes directly from the client to the edge. The autorouter is only involved once.
Thus, a voice agent making 50 inference calls per conversation (STT, LLM, TTS per turn) pays the routing cost once, not 50 times.
For stateless REST inference requests, failover is straightforward. The SDK detects a failure, tries the next-best node, and re-sends the request. The user might see an extra 100ms of latency on that single call. No state is lost.
Voice sessions are a different problem entirely. A voice agent conversation is stateful. Audio is streaming over WebRTC. The voice agent worker maintains conversation context, tracks what's been said, manages interruption state, and holds the dialogue history that shapes the next LLM call. If the edge node degrades mid-conversation, you can't just retry. The session state has to survive the migration.
This is the hardest routing problem we face, and we're honest about its current state. Seamless mid-call failover for streaming voice sessions is a genuinely hard problem in distributed systems. Our current approach is graceful degradation rather than transparent migration: finish the current conversational turn on the degrading node, then switch the client to a healthy node before the next turn. The user might notice a slightly longer pause between turns. They won't hear audio artifacts or lose conversation context.
The path to transparent migration involves making session state portable across nodes, either through shared state storage or through state reconstruction from the conversation log. Both approaches have tradeoffs in complexity and latency.
Edge inference introduces a constraint that centralized platforms don't face: model topology varies by node. Our RTX PRO 6000 nodes in Vancouver might run a quantized Llama. Toronto might run a Nemotron model variant optimized for a specific design partner's use case. Not every model is everywhere.
The router has to understand this topology. When a model is deployed to a node or purged to free VRAM, the autorouter's candidate list must update within seconds. If it takes minutes, the router is sending clients to nodes that will reject the request.
Multi-GPU nodes add another dimension where the router needs per-GPU configuration. We pin specific models to specific GPUs: gpu0 runs STT, gpu1 runs the LLM, and gpu2 runs TTS. A node might have available capacity on its STT GPU but be fully loaded on the LLM GPU. For a voice pipeline request that needs all three, that node is effectively at capacity even though aggregate metrics might suggest otherwise.
The Model Manager component handles deployment and lifecycle. When it loads or unloads a model on the Triton inference server, it publishes the updated availability matrix to the pub/sub channel. Autorouter instances subscribe to this channel and pick up the topology change on their next scoring cycle (sub-second). This tight coupling between model placement and routing is essential for an edge network where not every node is a clone of every other node. If the routing and compute layers are eventually consistent on a timescale of minutes, edge traffic drops.
A few principles that held up through the implementation.
DNS routing is table stakes, and the edge platform needs application-layer routing on top of it. DNS gets you to the right region, and the application gets you to the right node.
Client-side intelligence is underrated. The SDK is the closest observer to actual network conditions between the user and the edge. Delegating the final routing decision to the client produces better outcomes than any server-side heuristic. The client knows things about its own network that no central system can measure.
The router should be a decision service, not a proxy. In model routing for edge AI, the moment the router sits in the data path of every request, you’ve reintroduced the centralized hop you were trying to eliminate. Make the decision once, then get out of the way.
Failover for stateless requests is solved. Failover for stateful streaming sessions is the frontier, and it's where the genuinely hard distributed systems work lives.
We’re currently running edge nodes in Vancouver and Toronto. The routing architecture described here was designed for inference geo-distribution across a fleet of 15 to 60 nodes in North America. As we scale to more locations, more candidates per query means the discovery API’s response time matters more, model topology variation increases, and the probability of mid-session node issues grows with fleet size.
We're building this with real voice agent workloads. The constraints are real, the latency targets are measured, and the problems we haven't solved yet are problems we're actively working on.
Sev Geraskin, Co-Founder and VP of Engineering, PolarGrid
References:
Levinson, S. C., & Torreira, F. (2015). Timing in turn-taking and its implications for processing models of language. Frontiers in Psychology, 6, 731.
Stivers, T., et al. (2009). Universals and cultural variation in turn-taking in conversation. Proceedings of the National Academy of Sciences, 106(26), 10587-10592.